How many times does cat appear in the cat Wikipedia page?
In this post, I’m going to hit the Wikipedia API to get data into a database because so often as data engineers our job is to hit an arbitrary API and extract, clean, and store the data. The point of this post is not to showcase the best Python or software engineering skills ever. The point of this post is to talk through some common themes you may see in data engineering projects and to distract myself from my growing desire to cut my own hair. pleasehelpitkeepsgrowing.
The theoretical business ask is to record the number of instances of the word “Cat” and the most common word in the Wikipedia page on cats every day.
Okay first lesson: the art of good engineering is good Googling. I’m not promoting plagiarism; if you use someone’s code you should always credit them, but don’t reinvent the wheel. Your boss does not care if you wrote the code from scratch, your boss cares if it works.
So our first step is go to the Wikipedia page on their API. There we find the sample code for getting the content of a page, which we can slightly alter for our use case:
#!/usr/bin/python3
"""
parse.py
MediaWiki API Demos
Demo of `Parse` module: Parse content of a page
MIT License
"""
import requests
S = requests.Session()
URL = "https://en.wikipedia.org/w/api.php"
PARAMS = {
"action": "parse",
"page": "Cat",
"format": "json"
}
R = S.get(url=URL, params=PARAMS)
DATA = R.json()
print(DATA["parse"]["text"]["*"])
Now we get a bunch of HTML. It’s so ugly and long that we can’t tell what part we are on.
This isn’t going to work. We want to clean this text up a bit. There actually are libraries for parsing XML/HTML such as beautifulsoup. However, since we don’t need info from a specific tag (what is the header? What is the title?), but rather just to count instances of “cat”, I figured we could just brute force it.
This is what I ended up doing
## from https://stackoverflow.com/questions/9942594/unicodeencodeerror-ascii-codec-cant-encode-character-u-xa0-in-position-20
## strip and encode to UTF-8
convert_to_string = str(DATA["parse"]["text"]["*"].encode('utf-8').strip())
## from https://stackoverflow.com/questions/753052/strip-html-from-strings-in-python
## remove anything within an html tag
convert_to_string = re.sub('<[^<]+?>', '', convert_to_string) convert_to_string = re.sub('&#[^<]+?;[^<]+?;', '', convert_to_string)
## split on punctionality
## https://stackoverflow.com/questions/9797357/dividing-a-string-at-various-punctuation-marks-using-split
convert_to_string = re.sub('[?., %-()"^;:/]', ' ', convert_to_string)
## https://stackoverflow.com/questions/1546226/what-is-a-simple-way-to-remove-multiple-spaces-in-a-string
convert_to_string = re.sub('\\n', ' ', convert_to_string)
convert_to_string = re.sub(' +', ' ', convert_to_string)
## convert to lower
convert_to_string = convert_to_string.lower()
That was the extent of my brute force clean up. This gives us:
Because Wikipedia has citations and links at the bottom of the page, I decided to cut off the string as soon as we see the last “See also”:
end = convert_to_string.rfind("See also")
convert_to_string = convert_to_string[:end]
So once we’ve cleaned up the string of the whole page, you may be tempted to do something like “how many times does the string contain cat?” but that would give us false positives for words like domestiCATed. To get around this, we’ll change the string into an array, splitting on any space (notice before the in code we replaced all punctuation with a space and any number of spaces with one space).
word_list = []
word_list = convert_to_string.split(' ')
Now we have an array of words.

Your instinct may be to loop through and increment a variable named cat_counter every time you see a cat. Good instinct. But what about getting the most common word used? How would we do that?
Whenever I’m tempted to do a for loop and a counter, I ask myself if I can create a dictionary instead. I did this by:
word_dict = {}
for word in word_list:
word_dict[word] = word_dict.get(word, 0) + 1
This allows us to, every time we see a distinct word in the list, create a new entry for it in the dictionary. If the word has already been seen, we just increment that entry by 1. This works because when accessing a value associated with a key in a dictionary, you can do either:
- word_dict[“cat”] - this will return the value associated with cat but error out if cat is not a key in the dictionary
- word_dict.get(“cat”) - this will return the value associated with cat if it exists, if not it’ll return None
- word_dict.get(“cat”, 0) - this will return the value associated with cat if it exists, if not it’ll return the default, which, in this case, is 0
So the first time we see a word, we get 0 + 1 = 1. Then every time after that, we increment by 1. We then get this dictionary:
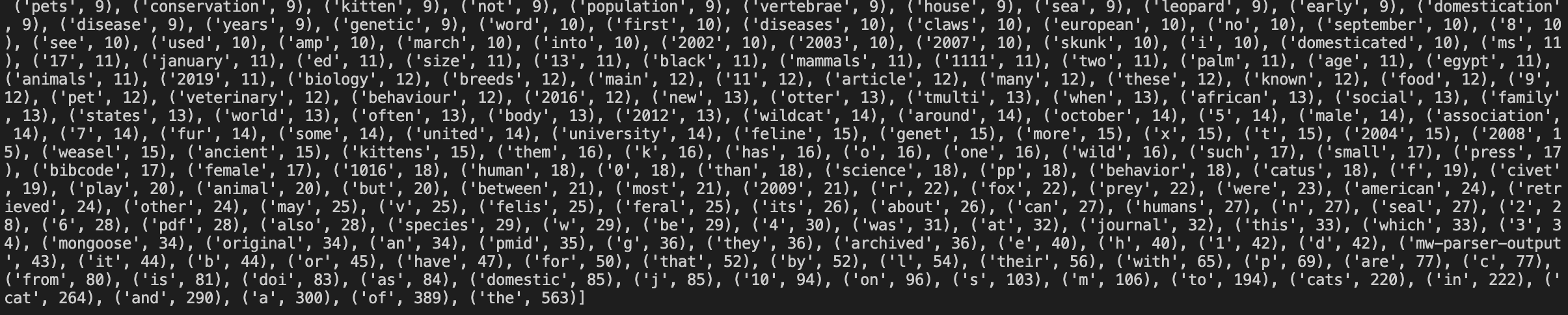
I actually sorted this dictionary to help us find the most common word.
sorted_word_dict = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
We passed a lambda function (an anonymous function) that tells the sorted function to sort by x[1], where x is the dictionary and x[1] is the value (as opposed to the key). reverse=True will make the most popular (biggest) value go first, so that way we can easily do the following:
cat_count = word_dict["cat"]
most_popular_word = sorted_word_dict[0][0]
Which gives us 264 times and the word “the”.
The only thing left to do is to write to our database, either directly via the Python connector or through a library such as SQLAlchemy. I am just going to create the INSERT statement:
EPOCH = str(time.time()).split('.')[0]
INSERT_STATEMENT = """ INSERT INTO cat_wiki_count (datetime_checked, cat_count, most_popular_word) VALUES ('{datetime_checked}', {cat_count}, '{most_popular_word}'); """.format(datetime_checked=EPOCH, cat_count=cat_count, most_popular_word=most_popular_word)
Things to note here:
- I’m recording the date and time that we found these results so there will never be dupes
- Datetimes as well as strings must be inserted with an additional straight quote around the parameter.
Let’s say your boss for wants you to only record the most recent data you find from the page and never the history. This is a bad idea; storage in databases is typically cheap and there is no reason why you can’t record all of history in this table and then get the most recent with SQL. But if it has to be done, just remember: never delete until you successfully insert.
So let’s say you did this:
DELETE_STATEMENT = "DELETE FROM cat_wiki_count;"
INSERT_STATEMENT = """
INSERT INTO cat_wiki_count (datetime_checked, cat_count, most_popular_word) VALUES ('{datetime_checked}', {cat_count}, '{most_popular_word}');
""".format(
datetime_checked=EPOCH,
cat_count=cat_count,
most_popular_word=most_popular_word
)
snowflake.execute(DELETE_STATEMENT)
snowflake.execute(INSERT_STATEMENT)
Now let’s say your insert statement failed. What are you left with? An empty table. Your boss wants the most recent, so if an insert failed, the truncate never should have happened. So how do we handle this?
We create a transaction using sqlalchemy and we rollback if our truncate failed:
engine = snowflake.engine
connection = snowflake.connect_engine()
transaction = connection.begin()
try:
connection.execute(DELETE_STATEMENT)
connection.execute(INSERT_STATEMENT)
except Exception as e:
transaction.rollback()
raise ValueError(e)
else:
transaction.commit()
finally:
connection.close()
This leverages:
- A transaction without autocommit, so actions can be rolled back. Usually, in our UI or IDEs we use autocommit so we don’t even think about it, but technically transactions such as DELETE and INSERT need to be committed. Read more about sqlalchemy transactions here. Basically, if either the DELETE or the INSERT fails, we rollback the transaction and the table goes to its state before the transaction started.
- All 4 parts of a try/except: try, except, else and finally. We leverage the
exceptto rollback the transaction if something bad happened, theelseto commit the transaction if it worked, and thefinallyto close the connection because, no matter what, we want to do that.
Again, I find it easier to just write from Python into Snowflake or any database with a timestamp and then deduplicate later in the SQL, but if you must delete records, be careful about it.
In this case, I fulfilled the requirement but let’s take a step back and think about scalability, validation, and flexibility.
Since Snowflake is great at storing semi-structured data and storage is cheap, is there any reason not to just store the entire dictionary of word usage as a variant? The benefits are:
- Keeps historic data - let’s say next week your boss wants to know the second most common word, how can you go back in time? If it’s not more effort or cost to store the entire dataset, consider doing that and parsing out what you need.
- Flexibility - what happens when your boss wants to check the dog page for the instances of the word dog? Do you make a dog_counter? This involves editing the Python code rather than just creating additional SQL. The most scalable version is a Python script that takes the name of a page, checks to ensure it found that page, and stores the count of each word:
#!/usr/bin/python3
import requests
import logging
import re
import time
import sys
import json
PAGES_TO_SEARCH = ["Cat", "Dog"]
URL = "https://en.wikipedia.org/w/api.php"
for page in PAGES_TO_SEARCH:
EPOCH = str(time.time()).split(".")[0]
word_list = []
word_dict = {}
sorted_word_dict = {}
## from https://www.mediawiki.org/wiki/API:Parsing_wikitext#GET_request
S = requests.Session()
PARAMS = {"action": "parse", "page": page, "format": "json"}
R = S.get(url=URL, params=PARAMS)
DATA = R.json()
## ensure the title page we're on is Cat
if DATA["parse"]["title"] != page:
print("something very bad happened")
sys.exit(-1)
## from https://stackoverflow.com/questions/9942594/unicodeencodeerror-ascii-codec-cant-encode-character-u-xa0-in-position-20
convert_to_string = str(DATA["parse"]["text"]["*"].encode("utf-8").strip())
## from https://stackoverflow.com/questions/753052/strip-html-from-strings-in-python
convert_to_string = re.sub("<[^<]+?>", "", convert_to_string)
convert_to_string = re.sub("&#[^<]+?;[^<]+?;", "", convert_to_string)
## split on punctionality
## https://stackoverflow.com/questions/9797357/dividing-a-string-at-various-punctuation-marks-using-split
convert_to_string = re.sub('[?., %-()"^;:/]', " ", convert_to_string)
##https://stackoverflow.com/questions/1546226/what-is-a-simple-way-to-remove-multiple-spaces-in-a-string
convert_to_string = re.sub("\\n", " ", convert_to_string)
convert_to_string = re.sub(" +", " ", convert_to_string)
convert_to_string = convert_to_string.lower()
end = convert_to_string.rfind("See also")
convert_to_string = convert_to_string[:end]
convert_to_string = convert_to_string.replace(r"\\u", "")
word_list = convert_to_string.split(" ")
for word in word_list:
if word.isalpha():
word_dict[word] = word_dict.get(word, 0) + 1
word_dict = json.dumps(word_dict)
INSERT_STATEMENT = """
INSERT INTO wiki_word_count (datetime_checked, page_name, word_count_json)
(SELECT '{datetime_checked}', '{page}', PARSE_JSON('{word_count}'));
""".format(
datetime_checked=EPOCH, page=page.lower(), word_count=word_dict
)
The table looks like this:

We can get the count of instances of the page name and the most common word with this query:
SELECT DISTINCT
datetime_checked,
page_name,
word_count_json[page_name] AS page_name_count,
LAST_VALUE(f.key) OVER (PARTITION BY page_name, datetime_checked ORDER BY f.value asc)
FROM wiki_word_count,
LATERAL FLATTEN(input => word_count_json) f

And there we have it– “the” is a pretty common word. If you learned anything from this post, I hope it was not that.