Table Types in Snowflake
Someone asked this question on Reddit
trying to build a data mart basically and most of the times it will be file source that will be transformed through ETL and eventually loaded into snowflake. So after that plan will be to build some views on top of these transformed tables which will be later used for data science purposes so wanted to know how to first approach building tables on snowflake (transient, permanent) i heard from some people suggesting to use transient tables in development environment So was getting confused what should be used when and how and when things like time travel should be enabled Along with that if there are best practices for roles accesses, data security, designing of tables and views will be great
I thought I could form it into a mini-post while helping my niece and nephew draw Pokemon pictures. They’re pretty good to be honest. This is really just a summary of table types from the Snowflake reference page and a little bit of important stuff I’ve learned from experience. Nothing revolutionary, not like Pokemon.
Time travel, transient tables, and fail-safe
What is time travel?
Time travel is the ability to retrieve older versions of your objects up to 90 days in the past (for enterprise customers; 1 day for non-enterprise). This includes the ability to undrop objects (tables, schemas, databases) which has saved more lives than CPR. Since you’re effectively storing copies of these objects, a longer time travel period will increase your storage costs. As they say, there’s no such thing as free data.
Reference: Storage costs for Time Travel
If you don’t want to time travel on an object, you can set the retention period to 0 days. Retention period, like a lot of Snowflake parameters, can be set at the account, database, schema or table level. The database or schema retention period is the default for each table made in that object; this can be overridden by a specific table retention.
A bit of advice: if you are doing CREATE OR REPLACE or DROP TABLE/CREATE TABLE for your tables every ETL run and you have time travel set, you will pay for time travel on each iteration of the table created. So let’s say your time travel is set to 3 days and each day you CREATE OR REPLACE TABLE cat_data AS SELECT * FROM cat_source;
Even though when cat_data is created it has the same table name, Snowflake regards it as a different table. So you will pay for time travel storage like this:
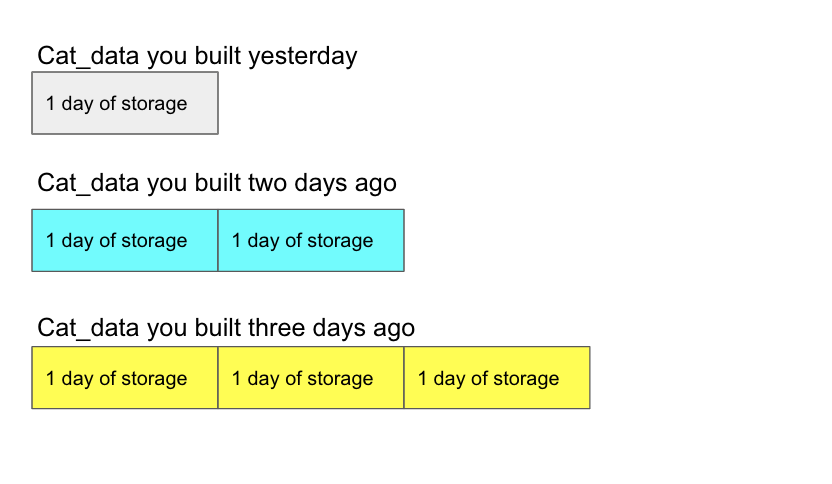
You will pay for 6 days of storage when really, it would be hard to reach any of it. The reason why you can hardly access it is because if you drop and recreate a table with the same name, it’s hard to retrieve it. I’ve struggled with it before; this will help you get it back but note it’s not trivial. In my opinion, time travel on CREATE OR REPLACE is just not worth the money. I recommend either not doing time travel for a CREATE/REPLACE or changing it to TRUNCATE/INSERT
What is fail-safe?
Snowflake reference
Fail-safe begins where time travel ends. Fail-safe is 7 days, no matter what, you can’t configure it. It’s like a week in that regard. Always 7 days. It is what it sounds like– your last resort in the event of a CATastrophe. Only Snowflake can access it, but you still pay for the storage.
What is a transient table?
A transient table is a table without fail safe! A transient table can still have time travel of up to 1 day, but it won’t be recovered in case of a complete database failure. So I would build transient tables for any table you don’t want more than 1 day of time travel on and you can easily re-build in case of a failure.
To refer specifically to the Reddit question, if you are just developing and it’s not yet production data, I may build transient tables, but, since I’m lazy, I’m more likely to set the retention period of the development database to 0 and pay for the fail safe. The reason is converting from transient to permanent isn’t easy and the DDL is different so you’d have to change all your DDL when moving to production.
Snowflake reference pages say “After creation, transient tables cannot be converted to any other table type,” but in reality, you would just clone the data into a permanent table:
CREATE OR REPLACE TABLE cat_permanent CLONE cat_transient;
So it’s not trivial and storage doesn’t cost that much, so I would just set my time travel preference by database.
What I like to use time travel for
I like to use time travel for:
Automated testing
For automated testing, time travel is good to see how the table looked 1 hour ago or 24 hours ago. You can track how all tables change in size over time and find trends to help you create alerts. This will give you size yesterday divided by size today:
select count(*)from cat_table at(offset => -60*60*24) /select count(*) as size_yesterday from cat_table
Note: I wouldn’t actually store that result in my QA dataset. I would store the count(*) at different times and then calculate the percent.
Ad-hoc QA and debugging
If there is an alert or even a question about “this suddenly looks different”, you can easily check both how a table looked an hour ago and how a table looked at before a certain commit.
If you look in your history tab and find that query ID catz123 is what updated the table last, you can check the before and after like:
select * from cat_table before(statement => 'catz123')
I may go as far as to do this following to find what existed before that is now gone:
select * from cat_table before(statement => 'catz123')
minus
select * from cat_table after(statement => 'catz123')
What I don’t like to use time travel for
I do not like to use time travel for retrieving historical data. If you really need historical copies, you should save them in a _history table. You have to pay for the storage either way, and storing it in a table is easy to access for stakeholders. For instance, instead of expecting stakeholders to do this:
select * from cat_table at(offset => -60*60*24)
to get the table from yesterday, at the end of every ETL, you can store that data into the cat_table_history table with a stored_timestamp column. Stakeholders can then query:
select * from cat_table_history where stored_timestamp = DATEADD('day', -1, CURRENT_DATE)
Ultimately, you’re going to pay the same storage anyway, and storing in a real table is easier to access and maintain. If you want to replicate the time travel attribute of 7 days, you can create a DELETE statement in your ETL as:
DELETE FROM cat_table_history WHERE stored_timestamp = DATEADD('day', -1, CURRENT_DATE)
I know what you’re thinking: but then this table will have time travel on it and we don’t need that. You can always turn time travel off on a specific table by doing:
alter table cat_data_history set data_retention_time_in_days=0;
Next I’ll write about views…