SQL Window Functions: I guess that's why they call it window pain
In this post, I will try to explain window (analytical) functions. As always, I will refer to their syntax in Snowflake, but the takeaways should apply to all relational database systems.
When I ask people if they know what window functions are the most common reply is to simply list all of the functions they can remember. I can tell from this reply that they have used them before, but they cannot fully articulate the class window functions belong to and what they are designed to achieve. Defining the properties of an entity demonstrates a better understanding of it than listing some of its potential values. Even an exhaustive list wouldn’t suffice; an object is more than the sum of its parts.
What is the definition?
My unofficial definition of window functions are “a function that allows you to operate on a subset of the rows in a table.” It’s a short definition for a large concept, but it’s easier than memorizing all possible functions.
Why are they so hard to understand?
I think part of learning what window functions are is understanding why they’re so difficult. When we begin learning SQL, we learn that any operation you do applies to the whole dataset:
- if you use a
where, it filters the whole table - if you perform an function on a column, it applies to the entire column
- if you do
group by, every aggregate field will be grouped by every non-aggregate field for the entire table
Our understanding of tables, entities, and datasets are that they have to be operated on in their entirety. If we want to operate in two different ways, we have to make CTEs, temporary tables, or subqueries and then join the two queries together. Each query of a table has its own grain and no one query can operate on two different grains. Or can it?
 Can two grains fit into one table?
Can two grains fit into one table?
So let’s start with what we learned originally and move towards window functions.
This is how I learned to find the name and date of a cat’s most expensive surgery. Note this will always allow duplicate surgeries per cat if they have the same cost.
SELECT
cat_surgeries.*
FROM cat_surgeries
INNER JOIN (
SELECT
cat_id,
MAX(surgery_cost) AS most_expensive_surgery
FROM cat_surgeries
GROUP BY 1
) AS surgery
ON surgery.most_expensive_surgery = cat_surgeries.surgery_cost
AND surgery.cat_id = cat_surgeries.cat_id
The reason you need two queries is because we are dealing with two grains: surgery info grain (the grain of the original table from which we want our data) and cat grain (the most expensive surgery per cat- the “per” tells me it’s on a cat grain). So can a window function help us with this problem?
How can we use window functions?
In this problem, we want to group (partition) by cat within the surgery table:
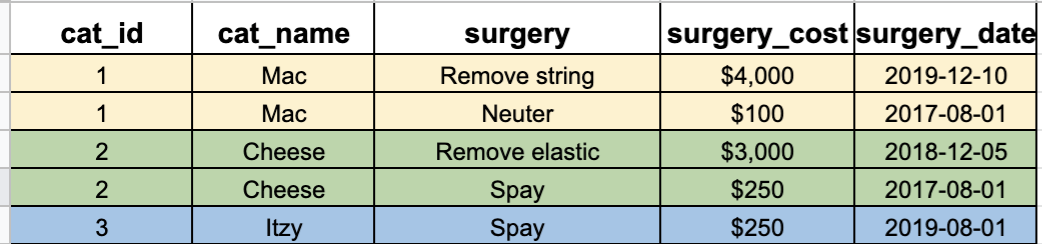
See how there are three partitions in the table? We then want to get the most expensive per partition:
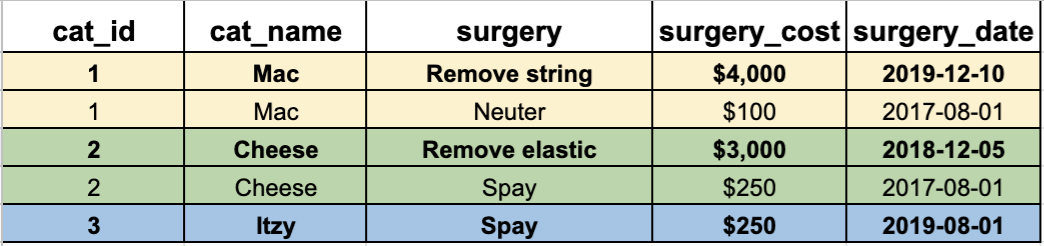
So how would we write this with window functions? There’s actually a few ways to get the information we are looking for (the most expensive surgery per cat).
With the ROW_NUMBER() function we can rank (but break ties) the cost of the surgery by cat. So removing string was Mac’s #1 most expensive surgery, while neuter is in lowly second place.
SELECT
cat_surgeries.*,
ROW_NUMBER() OVER (PARTITION BY cat_id ORDER BY surgery_cost DESC) AS expense_rank
FROM cat_surgeries

Another method would be for each cat finding the cost of their most expensive surgery using the MAX() function, so for Mac we see his most expensive surgery is $4,000. Notice especially in this case that the surgery field is on the surgery grain, but the max_surgery_cost is on the cat_id field. That is what makes these types of queries so hard to write.
SELECT
cat_surgeries.*,
MAX(surgery_cost) OVER (PARTITION BY cat_id) AS max_surgery_cost
FROM cat_surgeries

In order to select the row we need, we need to apply the qualify function, for example:
SELECT
cat_surgeries.*,
MAX(surgery_cost) OVER (PARTITION BY cat_id) AS max_surgery_cost
FROM cat_surgeries
QUALIFY max_surgery_cost = surgery_cost

Note that using the MAX() method we do not break ties, while the ROW_NUMBER() method does. RANK() or DENSE_RANK() would also leave the ties. For instance, let’s say Mac decided to spend more of my money, the final result may look like this:

For that reason, the possibility of duplicates and how you want to handle them should be front of mind when writing window functions.
 Hey Cheese, remember all those great times we have spent loads of mum’s money?
Hey Cheese, remember all those great times we have spent loads of mum’s money?
That wasn’t so bad! What else can I do with them?
Lots of stuff! You can even do running aggregates, such as running total using SUM()

SELECT
cat_surgeries.*,
SUM(surgery_cost) OVER (PARTITION BY cat_id ORDER BY surgery_date) AS running_total
FROM cat_surgeries
You can use LAG() and LEAD() to find the data right before this row or right after:

SELECT
cat_surgeries.* ,
LAG(surgery_date) OVER (PARTITION BY cat_id ORDER BY surgery_date) AS last_surgery_date
FROM cat_surgeries
You can even do tons of statistics stuff that I don’t understand!
Is that it?
No, there is more, but that is a big enough bite for now.
 Looking for more info on window functions…
Looking for more info on window functions…